Writing a Regular Expression to Target Images Without a Class
A while back, I wrote about building your own lazy loading functionality into WordPress. In that post, I use a regular expression to add a lazy-load class to image tags that don’t already have any class.
It failed. Rather than adding it to images with no preexisting class, it was added to every image, resulting in some images having two class attributes:
<!--- This is bad. --->
<img class="lazy-load" class="my-class" src="/img/path.jpg">
Thankfully, a couple of readers caught the issue, sending me back to the regex drawing board, and causing me to feel a little deserved shame for blindly borrowing that initial expression from deep within the crevices of the internet.
What Went Wrong
Here’s where I started. I thought I had an expression that would match img tags void of the word “class,” but instead, I had one that was finding matches way too eagerly.
$content = preg_replace(
'/<img(.*?)(?!\bclass\b)(.*?)>/i',
'<img$1 class="lazy-load"$2>',
$content
);
If you’re not already familiar with the preg_replace() method, read about it here. In short, it’s used to find matching regex patterns in a string, and then construct a new string that may or may not contain matching groups that have been captured (signified by $[number]).
Let’s toy with my initial expression. Take note of the first matching group: (.*?). This group matches any bunch of characters (including a string as small as zero characters in length) that is not immediately followed by the word “class,” as indicated by (?!\bclass\b). This all sounds like it should get the job done, but actually ends up matching a lot of stuff we don’t want, way too early on.
Here’s my string:
<img class="my-class" src="/img/path.jpg">
To start, the pattern matches the point immediately following <img in any image tag, since the next immediate character is not the initial boundary for the word “class,” but instead a space. Remember, the (.*?) group doesn’t require a match to have any length, so we get something like this:
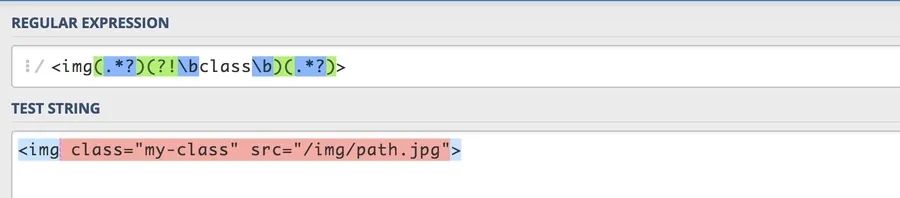

And because of this result, here’s how the string is processed by preg_replace():
<!-- Before: -->
<img [MATCH\][/MATCH] class="my-class" src="/img/path.jpg">
<!-- After: TWO class attributes!= -->
<img class="lazy-load" class="my-class" src="/img/path.jpg">
Swapping attributes makes no difference – there will always be a zero-length match after <img, since a space (and not a the beginning of the word “class”) always follows it. The lazy-load is always going to be added to that match, even when we don’t want it.
<!-- Before: -->
<img\[MATCH\][/MATCH] src="/img/path.jpg" class="my-class">
<!-- After -->
<img class="lazy-load" src="/img/path.jpg" class="my-class">
Unfortunately, adding an explicit space after <img to our pattern does nothing, because there’s guaranteed to always be at least one point at least zero characters long that meets the conditions of the expression.
$content = preg_replace(
'/<img (.*?)(?!\bclass\b)(.*?)>/i',
'<img $1class="lazy-load"$2>',
$content
);
<!-- Before: -->
<img \[MATCH\][/MATCH]src="/img/path.jpg" class="my-class">
<!-- After: FAIL -->
<img class="lazy-load"src="/img/path.jpg" class="my-class">
Or, with attributes reversed:
<!-- Before: -->
<img [MATCH]c[/MATCH]lass="my-class" src="/img/path.jpg">
<!-- After: FAIL -->
<img cclass="lazy-load"lass="my-class" src="/img/path.jpg">
This is where it made sense to experiment with the + quantifier, which, unlike the * quantifier, requires a match of at least one character. But yet again, that doesn’t help us much, because a match is nearly guaranteed to be found when progressing through each individual character of a string.
$content = preg_replace(
'/<img (.+?)(?!\bclass\b)(.*?)>/i',
'<img $1class="lazy-load"$2>',
$content
);
Similar markup, but shaken up attributes:
<!-- Before: -->
<img[MATCH]s[/MATCH]rc="/img/path.jpg" class="my-class">
<!-- After: FAIL -->
<imgs sclass="lazy-load"rc="/img/path.jpg" class="my-class">
What Worked
Clearly, my expression’s main fault was its tendency to find a match way too soon, without searching the entire img string to know if it has class= or not. So, after several hours of beating my head against a screen, I ended up with this.
/<img((.(?!class=))*)\/?>/Let’s take this real slow and piece it together from scratch.
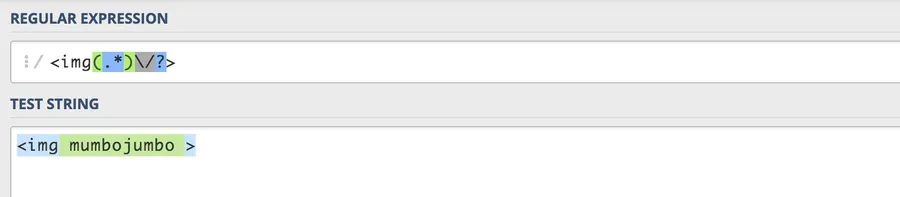
First, I knew I wanted to target img tags, which have an opening <img, followed by attributes and stuff (like a src, duh), and a closing bracket with an optional slash. Here are the components I started with:
/<img(.*)\/?>/Expectedly, this will match pretty much anything that has the shell of an img tag containing any characters, any number of times – signified by (.*).
And I know that within that shell, I’m just fine with matching anything – UNLESS it’s a class attribute. So, let’s modify that inner group. Rather than matching any character, let’s replace that character to target any character that is not followed by a class attribute.
/<img((.(?!class=))*)\/?>/Here are our updated components:
Here’s what we get for matches when we run it against our string:
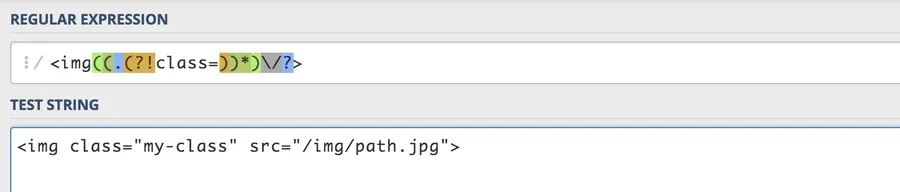
Great, no match!
And if we were to remove that class attribute:
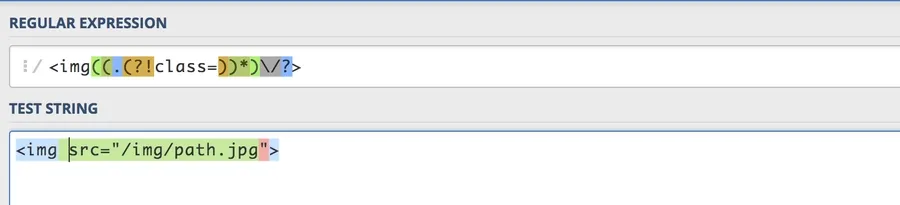
Nailed it! This should cover most of our scenarios, allowing us to accurately add a new class attribute only to the images that don’t have any. From what I can tell, the only time we would get a match is when class is butt right up against <img, when there would be no other character to precede the attribute.
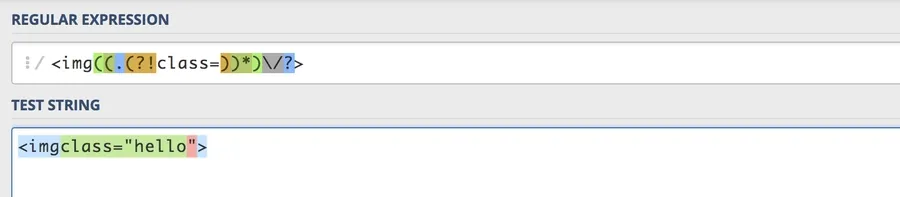
But that’s no longer a valid image tag, so that sort of risk really isn’t one at all. And with that, here’s our updated PHP call that should work exactly as we expect it.
$content = preg_replace(
'/<img((.(?!class=))*)\/?>/i',
'<img class="lazy-load"$1>',
$content
);
Takeaways
First, learning to break up & understand the fundamentals of regular expressions doesn’t need to be terrifying, especially if you’re patient and willing to start slow. This is, by far, the most significant thing with which I walked away from this process.
Second, with the patience & willingness to understand why regular expressions behave the way they do, stop trusting any given expression you find on the street. With a renewed confidence in tackling stuff like this, I’m much less likely to be burned in the future.
Finally, find a good tool you’re willing to get comfortable with as you break these things apart. I spent a lot of time with regex101. For you, it might be something different. That’s cool, just know what it is, so you can jump to it when it’s needed.
Thanks for embarking on this journey with me!
Get blog posts like this in your inbox.
May be irregular. Unsubscribe whenever.